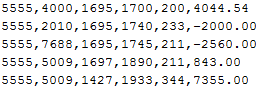In this blog I want to look at how to manage FDMEE maps. By that I mean a reliable and repeatable process for importing and exporting that is simple for the users and covers all the different maps. The process must take an export from FDMEE and create an import file in the correct format. Currently in FDMEE you can’t do this – there are problems with scripts, Data Load Rules, what is exported and what can be imported.
From an FDM point of view, it is very common to manage maps in Excel. It gives you a backup of the maps outside FDM and allows the maps to be reviewed, signed off and audited with a minimum of fuss and training. Using Excel for FDMEE maps is not the same. In FDM there were scripts to extract all the maps by location which could be scheduled to run once a month. This gives you a backup and an audit of the maps. You can do the same in FDMEE but it is a little more difficult because you have to write the scripts from scratch. In FDM you can import the maps through the Excel interface. You can do the same in FDMEE but it does not import all the map information and some of the data is not supported.
Scripts
The FDMEE Admin guide refers to scripts in maps as Conditional Mapping. These are the scripts that you write in Jython or SQL not the Multi-Dimensional maps. Exporting and importing these Jython/SQL scripts is problematic. In FDM, scripts in maps can be exported and imported through the Excel interface. That’s FDM, what about FDMEE? The Admin Guide says: “FDMEE does not support #SQL and #SCRIPT for Excel mappings”. OK so that just about kills that one dead then. The FDMEE Excel template is set up to include the VBScript column in the upload named range (and yes it is called VBScript even though the language is Jython/SQL). I have used the template for importing Conditional maps and it works. The problem is that the Admin guide says that it’s not supported. So is it that there is a problem with importing these scripts that I haven’t come across yet or have I strayed into a “consultants only” area? I don’t know but I am certain of one thing: if the manual says don’t do it then you need to have a very good reason for ignoring that.
Here is an overview of the functionality for exporting and importing:
Export – Excel
• Scripts are not exported from Data Load Mapping. The #SCRIPT/#SQL header record is exported but the actual script that is executed is not.
• In 11.1.2.4 all map information can be exported through the Excel Interface. In 11.1.2.3 you have to write a custom script to export all the map information or use LCM.
• Current dimension only.
• I have found that the Export to Excel sometimes produces a file with just the column headings.
Export – Text (Current Dimension and All Dimensions)
• Scripts are not exported from Data Load Mapping. The #SCRIPT/#SQL header record is exported but the actual script that is executed is not.
• Current dimension or All dimensions can be exported.
Import – Excel
• Importing scripts in maps (#SCRIPT/#SQL) through the Excel interface is not supported. Possible (?) just not supported.
• You can use LCM but that contains maps for the whole application and not just the maps for a single location.
• You cannot use the Excel Interface in 11.1.2.4 to import maps – it does not increment the DataKey column correctly and it will corrupt the maps.
• You can write a custom script that reads a text file and imports these Conditional maps.
Import – Text (Current Dimension and All Dimensions)
• Importing scripts in maps (#SCRIPT/#SQL) through text files is not possible.
In summary, exporting and importing scripts in maps is difficult. I keep scripts in maps down to absolute minimum. I always have an external backup of the scripts because I use Notepad++ not the internal editor.
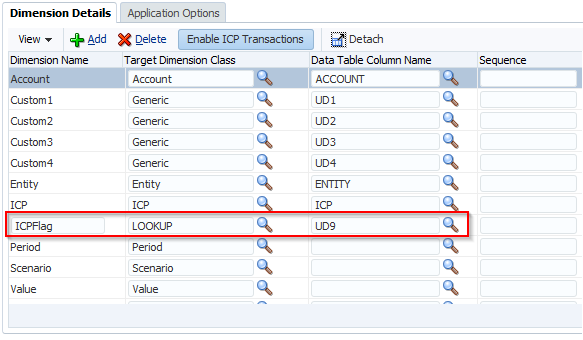
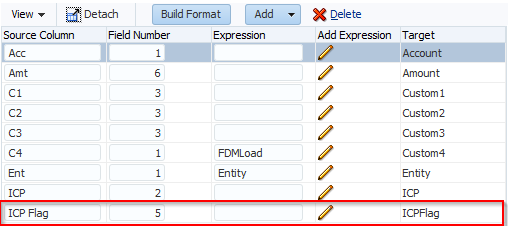
Data Load Rules
A map can be restricted to a Data Load Rule and this information can be exported and imported. The problem here is in the Excel interface because it uses the Data Rule Name id not the name. The default Excel template that can be downloaded from FDMEE does not include the Data Rule Name column in the named range. You can change the named range to include the column but you must make sure you use the id not the name.
Suggested strategy
Above all, we want a reliable method of exporting and importing all the relevant map information. That means it must be text format – the Excel route is one dimension at a time for export, does not always work and the Data Load Rule is tricky. There are two problems we need to overcome: Scripts and Data Load Rules. If we use text format the Data Load Rule problem is fixed; you can just add the name of the Data Load Rule. That leaves the maps with scripts and a simple way of getting around this problem is not to use them. It’s not enough to say ‘don’t use them’ because there are times when you don’t have a choice. So we will look at a great alternative to scripts in maps: Multi-Dimensional maps.
Multi-Dimensional maps
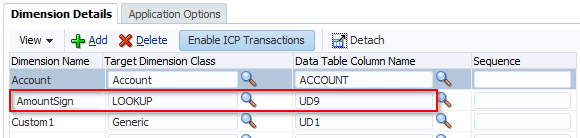
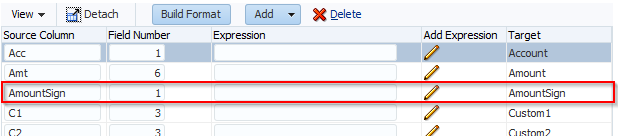
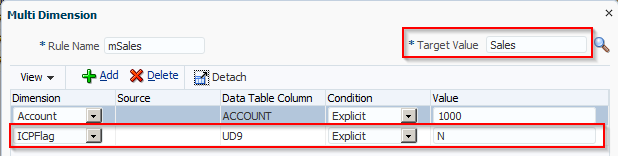
Scripts in maps are used to do what is not possible in standard maps such as check the target values in other dimensions or map based on the data amount. We know we can use Multi-Dimensional maps to reference the source values in other dimensions. What the manual does not tell you is that with Multi-Dimensional maps you can reference target dimensions, the amount, specify ‘not’ conditions etc. The workspace won’t let you do any of this but the text file will. NOTE: this has been tested on a SQL Server database; things might be different on Oracle.
Here is an example of a multi-dimensional map in a text file:
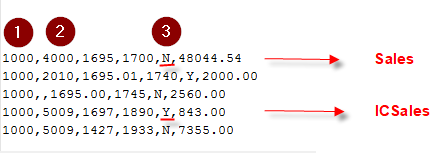
UD2,#MULTIDIM UD1=[OtherInterest],INTOTH,mINTOTH,,
This is saying if the source Custom1 member is OtherInterest, then map Custom2 to INTOTH. The rule name is mINTOTH. You can reference the Target dimension by adding X to the end of the dimension name. So if I change UD1 to UD1X it will look at the Target Custom1 member:
UD2,#MULTIDIM UD1X=[OTHINT],INTOTH,mINTOTH,,
That means if the Target Custom1 member is OTHINT, then map to INTOTH. You can’t edit these maps in the workspace – they have to be managed in the text files.
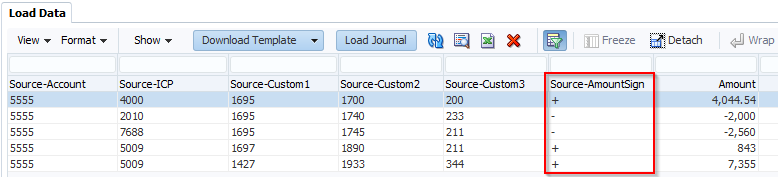
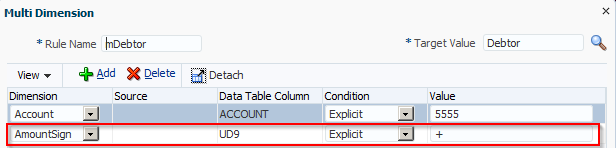
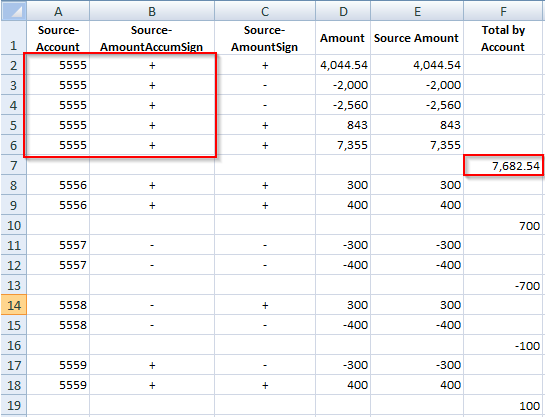
You can also reference the data amount by using the AMOUNT or AMOUNTX column so, as an example, map to one account if it’s a credit and another if it’s a debit. The Multi-Dim map only works if there is an equals sign (=) so if you want to map based on amounts you must use <= or >=:
UD2,#MULTIDIM AMOUNT >=[0],POSITIVE,mTEST_P,,
UD2,#MULTIDIM AMOUNT <=[0],NEGATIVE,mTEST_N,,

There have been many occasions when it would have saved a lot of time and mapping if I could just have said if the source does NOT begin with 8 (for example) then map here. Well you can do that too using Multi-Dims. Again the key here is that the Multi-Dim part in the text file must contain an equals sign so we use != instead of <>:
UD2,#MULTIDIM Account !=[1100],OHDETOTH,MOHDIRECT,,
So if the Account is not equal to 1100, then map the Custom2 member to OHDETOTH. And this is how it looks in the workspace:
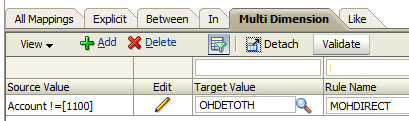
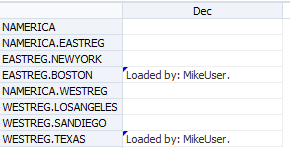
On the downside though there is a laughable bug in Multi-Dim maps. I say laughable because when I first saw it I thought it was funny. It’s not so funny when you try and find a way around it however. I have only tested this on 11.1.2.3 so it might be fixed in 11.1.2.4. Anyway, the bug is if the source value contains OR in capitals, then FDMEE thinks it is a keyword. So CORE becomes C”OR”E:
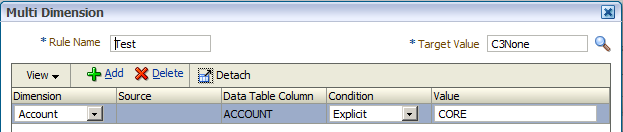
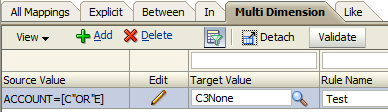
The workaround is to use lower case but if your database is Oracle, then you will probably need to think of something else.
Conclusion
Using Multi-Dimensional maps is a great alternative to Jython or SQL scripts. It means that you can have a safe and reliable way of importing and exporting maps. There are some things Multi-Dim maps can’t do but they have greatly reduced the need for scripts. Now use Excel as a front end to these text files (import and export) and you have a robust and easy to use way of managing and backing up the maps.